Parameter overview
Parameter data is provided in .csv csv files starting with par_ and transferred into ParElement objects. The read-in data is used by the inheritance algorithm to compile the parameter data being used in the model's underlying optimization problem. This avoids huge but largely redundant input files and allows for lean and flexible models.
Read-in
In contrast to sets, the naming of parameter files and what data is provided in which file is entirely up to the user. For instance, data for the same parameter can be spread across different files and within one file multiple parameters can be defined.
Pivot format
Parameter data is provided in a pivot format where the column parameter determines the respective parameter and the column value its respective value. Additional columns specify the nodes within the hierarchical trees of sets a value applies to. Therefore, names of these columns are comprised of the set's name and, if the set is organized in a tree with multiple levels, the number of the respective level.
The all keyword can be used analogously to sets (see Time-steps). Columns that do not contain a set name (i.e. region, timestep, carrier, technology, mode, or id) or keyword (i.e. parameter and value) are not read in and can be used for documentation. To define multiple parameters within the same row, several numbered parameter/value columns can be provided (see par_techCost.csv).
As an example, the table below shows the definition of the discount rate parameter in the demo model found in the par_techInvest.csv file.
| timestep_1 | region_1 | region_2 | parameter | value |
| West | rateDisc | 0.0 | ||
| 2030 | West | WestSouth | rateDisc | 0.015 |
| 2030 | East | rateDisc | 0.03 |
In case, a set is included in the dimensions of a parameter, but no node of that set is assigned for a respective value, the very top node of the tree is assigned instead.
Multiple dependencies on same set
Parameter can depend on multiple instances of the same set. In case of an emerging technology (see section on optional mappings for technologies)
efficiency for instance can depend on two different kinds of time-steps: $Ts_{dis}$, the time-step a technology is being used, and $Ts_{exp}$, the time-step a technology was built. Following the order of sets in the definition, the first time-step specified in the input data will always relate to $Ts_{dis}$ and the second to expansion $Ts_{exp}$.
Accordingly, in table below the first column relates to $Ts_{dis}$ and the second to $Ts_{exp}$. Consequently, the specified efficiency applies to the first hour of every year for all heatpumps constructed 2020.
| timestep_4 | timestep_1 | technology_1 | parameter | value |
| h0001 | 2020 | heatpump | effConf | 5.0 |
This concept equally applies if one of the sets is defined by more then one column. In the table below, the first and the second column are attributed to specify $Ts_{dis}$. Since the third column goes back up to the first level, AnyMOD realizes it refers to a different dimension and attributes it to $Ts_{exp}$. As a result, both efficiencies apply to heatpumps constructed 2020, but one row relates to the first hour of 2020 and the other to the first hour of 2030. So, this example also shows how the aging process of technologies can be modelled.
| timestep_1 | timestep_4 | timestep_1 | technology_1 | parameter | value |
| 2020 | h0001 | 2020 | heatpump | effConf | 5.0 |
| 2030 | h0001 | 2020 | heatpump | effConf | 4.5 |
Inheritance
The combinations of sets or instances parameters are provided for within the input data do not need to match the instances required within the model. The required values are automatically compiled from the data provided. This facilitates the provision of input data and allows for a high level of flexibility in modelling.
If, for example, for one technology efficiency should be dependent on the time-step and for another irrespective of the time-step, this can simply be achieved in the model by providing efficiencies with an hourly granulation in the first and without specifying the temporal domain in the other case. In the demo problem for instance, heat-pump efficiencies are provided hourly in par_heatpumps.csv while for all other technologies par_techDispatch.csv defines efficiencies without specifying a dispatch time-step.
Poorly provided input data, especially time-series data, can massively increase the run-time of the inheritance algorithm. For example, if your raw data is provided quarter-hourly, but the most detailed resolution you actually want to model is hourly, you should aggregate the data to hours yourself before providing it to the model. To define a quarter-hourly resolution below the hourly resolution, feed-in the unaltered data and have the inheritance algorithm aggregate it instead, is possible but highly inefficient.
Modes of inheritance
When data is required but not defined for a specific combination of nodes, the algorithm moves along the vertices of the set trees to derive it. There are four different modes to do this, that will be explained based on the graph below. It shows the hierarchical tree of time-steps in the demo problem with data specified for some nodes (green), but not for the one required (red circle).
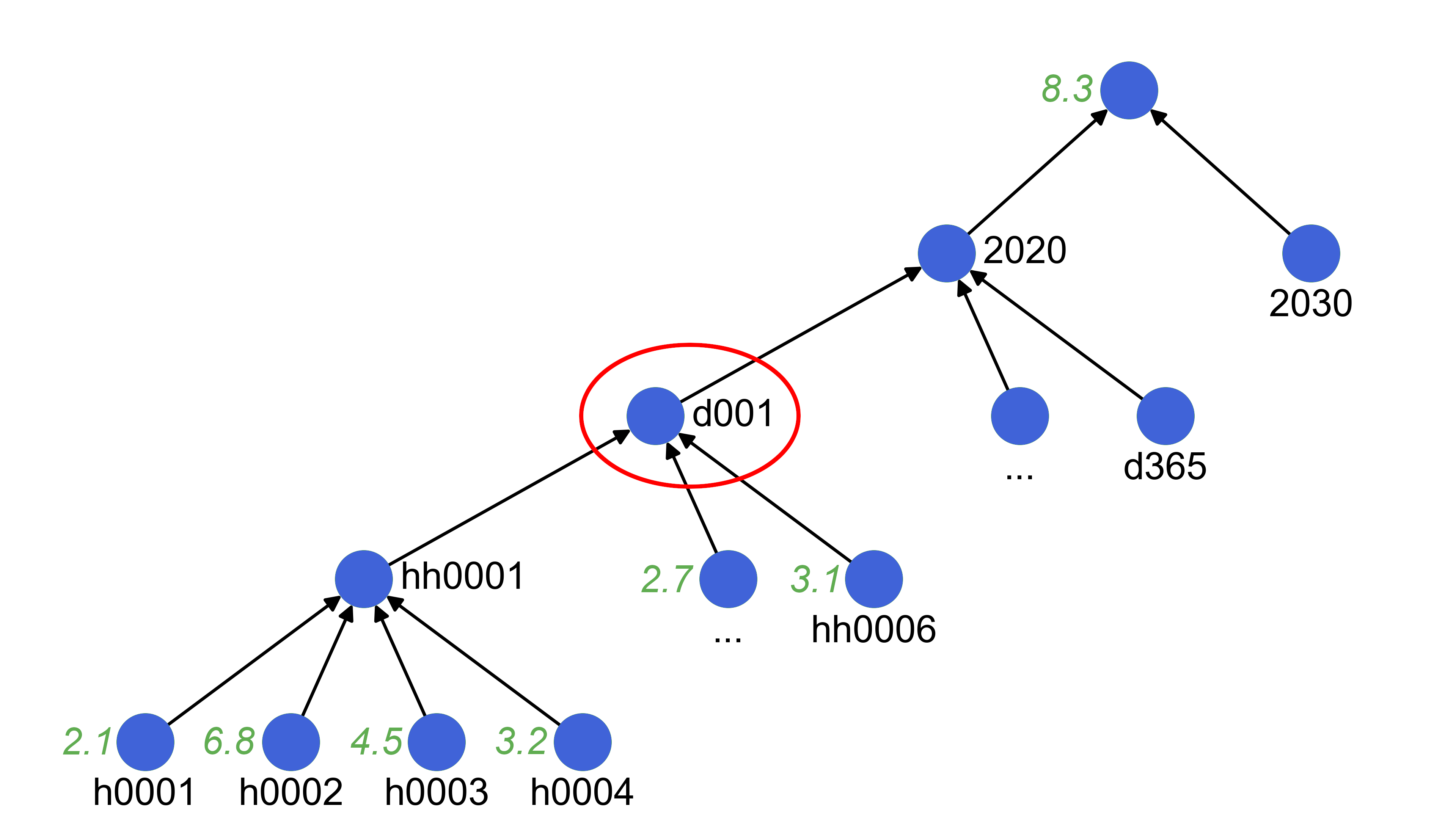
- upwards
Moving upwards the tree until a node with data is reached. In the example this means to assignd001the value8.3. If data would already be provided for2020, the direct ancestor ofd001, this value would be used instead. - average
Moving downward until nodes with some data are reached and take the average of those value. In the example this means to assignd001the value2.9($=\frac{2.7 + 3.1}{2}$). - sum
Moving downward until nodes with some data are reached and take the sum of those value. In the example this means to assignd001the value5.8($=2.7 + 3.1$). - sum*
Moving downward until nodes who all have data assigned are reached and take the sum of those value. In the example this means to assignd001the value16.6($=2.1+6.8+4.5+3.2$).
Inheritance algorithm
The actual algorithm is outlined for the example of the discount rate parameter from the demo problem. The instances of the parameter required with in the model are given below, the provided input data was shown above.
| timestep_superordinate_dispatch | region_expansion |
| 2020 | West < WestNorth |
| 2030 | West < WestNorth |
| 2020 | West < WestSouth |
| 2030 | West < WestSouth |
| 2020 | East < EastNorth |
| 2030 | East < EastNorth |
| 2020 | East < EastSouth |
| 2030 | East < EastSouth |
| 2020 | East |
| 2030 | East |
| 2020 | West |
| 2030 | West |
Three steps are taken to populate the table with the required data:
- Direct matches
First, values are assigned where instances of the required data exactly match the provided input data. For example, data for
2020andWestSouthis specifically provided and can be used directly.timestep_superordinate_dispatch region_expansion value 2020 West < WestNorth 2030 West < WestNorth 2020 West < WestSouth 2030 West < WestSouth 0.015 2020 East < EastNorth 2030 East < EastNorth 2020 East < EastSouth 2030 East < EastSouth 2020 East 2030 East 0.03 2020 West 2030 West - Go along inheritance rules
Next, the algorithm consecutively applies the inheritance rules of the respective parameter. For each parameter these rules are documented in the parameter list. These rules assign sets to the modes of inheritance introduced above.
- $Ts_{sup}$ → upwards
For discount rates, the first rule is to try to obtain additional values by moving upwards in the hierarchical trees of time-steps. In the first row of input data, a value was provided irrespective of time-step, but only for the region
West. This value is now assigned to the missing entries of that region.timestep_superordinate_dispatch region_expansion value 2020 West < WestNorth 2030 West < WestNorth 2020 West < WestSouth 2030 West < WestSouth 0.015 2020 East < EastNorth 2030 East < EastNorth 2020 East < EastSouth 2030 East < EastSouth 2020 East 2030 East 0.03 2020 West 0.00 2030 West 0.00 - $R_{exp}$ → upwards
Next, the concept is analogously applied to regions. By moving up the tree the value provided for
Eastis now assigned for the descendant regionsEastNorthandEastSouthas well.timestep_superordinate_dispatch region_expansion value 2020 West < WestNorth 0.00 2030 West < WestNorth 0.00 2020 West < WestSouth 0.00 2030 West < WestSouth 0.015 2020 East < EastNorth 2030 East < EastNorth 0.03 2020 East < EastSouth 2030 East < EastSouth 0.03 2020 East 2030 East 0.03 2020 West 0.00 2030 West 0.00 - $Ts_{sup}$ → average and $R_{exp}$ → average
The average mode tries to inherit values from descendant carriers. In this case, for none of these any data is defined, and consequently no additional data can be compiled.
- $Ts_{sup}$ → upwards
- Use default value
Finally, for all cases where no data was assigned, the default value is used instead. In case a parameter does not have a default, cases are dropped.
timestep_superordinate_dispatch region_expansion value 2020 West < WestNorth 0.00 2030 West < WestNorth 0.00 2020 West < WestSouth 0.00 2030 West < WestSouth 0.015 2020 East < EastNorth 0.02 2030 East < EastNorth 0.03 2020 East < EastSouth 0.02 2030 East < EastSouth 0.03 2020 East 0.02 2030 East 0.03 2020 West 0.00 2030 West 0.00